Question> I need to find out how and What TeraSync Tables are in Datastage using Teradata
The Teradata DBA says these are a Datastage thing.
What is the purpose of these Tables? Can these be shut off? Are these tables used with the TD Connector as well ?
Answer> The Teradata sync tables are indeed created by certain DataStage stages. Teradata Enterprise creates one named terasync that is shared by all Teradata Enterprise jobs that are loading into the same database. The name of the sync table created by the Teradata Connector is supplied by the user, and that table can either be shared by other Teradata Connector jobs (with each job using a unique Sync ID key into that table) or each Teradata Connector job can have its own sync table.
These sync tables are a necessity due to requirements imposed by Teradata's parallel bulk load and export interfaces. These interfaces require a certain amount of synchronization at the start and end of a load or export and at every checkpoint in between. The interface requires a sequence of method calls to be done in lock step. After each player process has called the first method in the sequence, they cannot proceed to call the next method until all player processes have finished calling the first method. So the sync table is used as a means of communication between the player processes. After calling a method, a player updates the sync table and repeatedly checks the sync table until all the other players have also updated the sync table.
In Teradata Enterprise, you cannot avoid using the terasync table. In the Teradata Connector, you can avoid using the sync table by setting the Parallel synchronization property to No, however that stage will be forced to run sequentially in that case.
Problem(Abstract) Ulimits are determined by the dsrpc daemon process for all process spawned by the Conductor on an SMP environment, however, when you introduce additional processing nodes (MPP) Ulimits need to be addressed on those nodes separately.
Symptom Changing ulimit in the conduct node does not resolve the error - One symptom of this error: Fatal Error: Need to be able to open at least 16 files; please check your ulimit setting for number of file descriptors [sort/merger.C:1087]
Cause On UNIX/Linux MPP configuration the ulimit are set for the user running the processes on the processing nodes, They are not inherited from the Conductor like the rest of the environment.
Environment MPP on Unix/Linux
Resolving the problem Each users that "owns" processes on the remote processing nodes (where the Conductor spawns processes on remote processing nodes as that user) needs to have their ulimit set correctly on EACH processing node. This can be done by either setting the default ulimit for everyone, or setting each user's ulimit specifically.
An example for AIX:
Modify the /etc/security/limits file's default settings as root user:
The default section is used to set the defaults for all users, You can override each user in the same manner.
A note about ulimit nofiles (number of open files) on 64-bit AIX. You should not set nofiles to -1 (unlimited) or nofiles_hard to unlimited on AIX running a 64 bit kernel. This will cause an integer overflow for Information Server and you will get a variation of the error listed above.
Problem(Abstract) The IBM InfoSphere DataStage client applications cannot connect to the InfoSphere DataStage server when the TCP/IP ports are not available through firewalls for the application server.
Symptom An error message similar to the following message is displayed:
Failed to authenticate the current user against the selected Domain
A communication failure occurred while attempting to obtain an initial context with the provider URL: "iiop://s6lpar50:2825". Make sure that any bootstrap address information in the URL is correct and that the target name server is running. A bootstrap address with no port specification defaults to port 2809. Possible causes other than an incorrect bootstrap address or unavailable name server include the network environment and workstation network configuration. javax.security.auth.login.LoginException: A communication failure occurred while attempting to obtain an initial context with the provider URL: "iiop://s6lpar50:2825".
Resolving the problem Before you install IBM InfoSphere Information Server, assess and configure your network to ensure that the IBM InfoSphere DataStage client applications can connect to the InfoSphere DataStage server when the WebSphere Application Server is behind a firewall. To configure the application server ports:
In the WebSphere Application Server administrative console, expand the application server list in the Servers > Application servers, and then select server1.
In the Communications section, select Ports.
Open the ports for the firewall configuration.
Use the following list to identify the ports that are required for your network configuration.
To access the application server behind a firewall, open the following ports:
WC_defaulthost
BOOTSTRAP_ADDRESS
ORB_LISTENER_ADDRESS
SAS_SSL_SERVERAUTH_LISTENER_ADDRESS
CSIV2_SSL_MUTUALAUTH_LISTENER_ADDRESS
CSIV2_SSL_SERVERAUTH_LISTENER_ADDRESS
To use HTTPS to access Web clients, open the following port:
WC_defaulthost_secure
To access the WebSphere Application Server administrative console, open the following port:
WC_adminhost
To use HTTPS to access the WebSphere Application Server administrative console, open the following ports:
WC_adminhost_secure
To publishing services using a JMS binding, open the following ports:
Question> We are unable to trigger any DataStage jobs from SAP. When I try to invoke a DataStage job from SAP infopackage in a BW Load - PULL operation, I see this message in the log:
> cat RFCServer.2010_02_26.log 2 I: BW Open Hub Extract: Data ready for BW initiated job. InfoSpoke Request ID 306696. Fri Feb 26 09:45:00 2010 4 I: BW Load: Notifying push job request REQU_4GZ0F9G5SIAEE283M04XSUM9G is ready at Fri Feb 26 11:08:55 2010
But the DataStage job is not triggered. The info package keeps waiting forever to receive data but the DataStage job that provides data never gets triggered.
Answer> Running jobReset to cleanup the temporary files: Open a command prompt window to the DS Server and: 1. source dsenv: cd /Server/DSEngine . ./dsenv 2. run the job reset utility cd $DSSAPHOME/DSBWbin ./jobReset where = MASTER | MASTERTEXT | TRANSACTION | MASTERHIERARCHY for example: cd /hpithome/IBM/InformationServer/Server/DSBWbin ./jobReset SAPBW8 PACK09 IS1 MASTER bwload You should get a confirmation message: "jobReset - Successful"
If there will be any issues with respect to the connectivity, then the logs created under the directory as listed below:
Check out the Designer logs in for more details on the error you're seeing.
Client machine logs C:\Documents and Settings\_Windows_Username_\ds_logs\dstage_wrapper_trace_N.log (where N cycles from 1 to 20, to give you the log files for the last 20 DataStage sessions)
Question> Is there any way how to influence the size of tsortxxxxx files that are created in the Scratch directory? We are running a PoC at the customer size and we have more than 70 mil records that has to be sorted. It leads to more than 5000 tsortxxxx files created in the Scratch directory. When these files are read in the next join stage, the performance is extremely slow because of necessity of access to this big directory. Each of the file has a size of approx. 10MB. Is there any way how to increase the file size and what are advantages and disadvantages of this approach?
Answer> The size of the files are controlled through the use of the "Limit Memory" option in the Sort Stage. The default size is 20MB. What you are actually controlling is the amount of memory allocated to that instance of the sort stage on the node. The memory is used to buffer incoming rows and once full it is written to the sort work disk storage (in your case the Scratch directory). Increasing the size of the of the memory buffer can improve sort performance. 100-200MB is generally a decent compromise in many situations.
Advantages: -- Larger memory buffer allows more records to be read into memory before being written to disk temporarily. For smaller files, this can help keep sorts completely in memory -- The larger the memory buffer, the fewer i/o operations to the sort work disk and therefore your sort performance is increased. Also, a smaller number of files leads to fewer directory entries for the o/s to deal with
Disadvantages: -- Larger memory buffer means more memory usage on your processing node(s). With multiple jobs and/or multiple sorts within jobs, this can lead to low memory and paging if not carefully watched. -- This option is only available within the Sort stage...it is not available when using "link sorts" (sorting on the input link of a stage). If your job uses link sorts, you will have to replace them with Sort stages in order to use this option.
Be careful when tuning with this option so that you don't inadvertantly overtax system memory. Adjust and test and work towards a compromise that gives you acceptable performance without overloading the system.
Question> Our customer forgot to purge logs in DB so in several days LOGGING_XMETAGEN_LOGGINGEVENT1466CB5F table growed to enormous size. They switched to FS logging and set up log purging. Now they want to get rid of the data in that table.
I think it will be safe enough to delete rows from there (using db load of course) and they to reorginize it to free up the space. Table reorg will drop the table and recreate it and this part worries me a bit. AFAIK there are no foreign keys and if WAS is down, I don't think there will be a problem to drop and recreate the table, but still ... What are the official procedure to do this task?
I saw an email about using LoggingAdmin.sh and then reorg, but I wanted to be sure that reorg (that will DROP the table) doesn't cause any problems (it's production environment).
Answer> You can use the purge function available in web console but this will take long time to finish for this data size
This is what i use to delete all logging events from xmeta table
1. Create an empty file "empty.id"
2. execute this command. File empty.id should be in this directory
db2 import from empty.id of del replace into xmeta.logging_xmetagen_loggingEvent1466cb5f
Question> I need to create a sorted seq file of about 31 millions of rows. Running the sort stage sequentially (with 167 columns, 3 of them are the sort keys) takes about 3 hours and 10 minutes to land all the data.
Is there any technique I can use to boost the performance?
Answer> just to inform you I was able to drop the elapsed of my test job from 3 hours to 1 hour for about 32 millions of rows What I've done is: 1 . remove the length of varchar fields and decimal fields 2 . convert the decimal field to varchar but I've got the same throughput converting decimal fields to double, the problem was the output format. 3. create one big varchar field (without length) containing all the fields not part of the sort key
With RTLogging = 1 you enable old fashion logging (on Universe) and you have to disable the repository logging (ORLogging = 0)
Question > If i understand well, logs must be put in universe repository for job controls to operate correctly. Right? What if the customer argues that migration to xmeta seems to be incomplete? what if the customer wants logging in new repository and job controls to still operate? Btw, it seems to me that it should work that way, no?
Answer> No, the logs can be in either repository, and all APIs should work (give the same results) in either case. The RTLogging version is much faster and scales better - that should be the only difference
Question> What is the pros & cons of ORLogging versus RTLogging?
Is it really because the repository cannot scale to support the ORLogging or we don't know the right setting. I believe DB2/Oracle can handle hundreds of thousands transactions per second with the right configuration.
Answer> You are quite right about the database performance.
However, the implementation of ORlogging is not designed for performance. The actual table has many DBCLOB (double byte character large object) columns - and this is in reality preventing high performance.
As far as I know DB2 does not hold large object-tables in the buffer pool - so every update to such a table will trigger I/O - and waits.....
Does anyone have an exact customer scenarios that has ORLogging failed because of performance. How many logging events were being logged at the moment of poor performance? workload description? is there a purging mechanism in place?. I would like to include the scenarios to test it for IS8.5.
Answer> I had better answer this following my previous comments......... ;-)
November 2008 I installed v8.1 on a windows box (Windows Server 2003 Enterprise Edition). I don't remember the specs of the server - except that I am sure it had 16 GB memory.
Of the Information Server products only DataStage was installed (no Information Analyzer, no Business Glossary etc.).
The installation was similar to the client's other systems running v8.0.1 - and was tested with existing jobs.
A couple of server jobs (imported from an v7.5 export) threw a warning for every row during test. This made Director quite unresponsive, showing no log records for jobs in status finished if it responded at all. It turned out LOGGING_XMETAGEN_LOGGINGEVENT1466CB5F had around 800.000 rows. I deleted something like 780.000 records with:
delete FROM XMETA.LOGGING_XMETAGEN_LOGGINGEVENT1466CB5F where cis13_xmeta = 'MultiBomFinal'
MultiBomFinal was the job responsible for around half a million log records - logs for a couple of other jobs were deleted as well.
Following this I switched the installation to RTLogging.
While the technical solution was straight forward this did nothing to improve the client's impression of Information Server - and they were not too happy as it was (long story - mostly not our fault).
Question> We have installed 8.1 at this client site and I have been here for a year. The response times has been pretty bad -- mainly due to the poor network at the client site.
I understand the difference between RTLogging and ORLogging -- thanks to techlist -- but we dont want to change it midway of this project and get into some unexpected problems.
Over a period of time the DEV system has over 1000 jobs and logging is set to ORLogging -- hence or otherwise we are noticing poor performance overall.
Since it is the dev system, we want to improve the performance and we dont care about saving old/previous logs.
Are there any steps to clear out the logs completely while maintaining it as ORLogging? I am hoping that doing that will improve the performance a little bit. Can somebody point me to the documentation relating to this?
Answer> If you do not care about saving logs you can use either the web console or db2 sql commend to purge logs for the ORLogging setup
Using WebConsole ================= 1. Login to web console and navigate to Log Management/LogView as shown here. you should see the log view for your job else create one Bby clicking on New Log View 2. Select the Log View that you use to view your OR logging events in xmeta and Click on "Purge Log" on the left navigation 3.Using sql ========
Here are steps to remove all rows in the logging table
as db2inst1 (Instance owner)
1) db2 "select count(*) from xmeta.LOGGING_XMETAGEN_LOGGINGEVENT1466CB5F"
record the number of rows in this table
2) create an empty file called empty.txt
3) db2 "import from empty.txt of del replace into xmeta.LOGGING_XMETAGEN_LOGGINGEVENT1466CB5F"
If you hit -964 then you need to increate logfilsize and increate LOGPRIMARY or cobination of both.
Link http://publib.boulder.ibm.com/infocenter/iisinfsv/v8r1/topic/com.ibm.swg.im.iis.common.ic.doc/common/iiypcmic_personalizing_table_of_contents.html
Personalizing the information center by narrowing the search scope
You can narrow the search scope by product or focus area. Narrowing the search scope is helpful if you are working with only a subset of the products or features. Follow these steps to search only specific sections, based on the organization in the Contents view.
To narrow the search scope:
Click the Search scope () link next to the Search field. The Select Search Scope window opens.
Select Search only the following topics and click the New button. The New Search List window opens.
In the List Name field, type a name for your search filter. The OK button remains unavailable until you provide a list name.
In the Topics to search list, select the categories that you want to include in your search. You can expand categories to select only certain subcategories.
Click OK.
Click Search only the following topics.
Select the search list that you created. Click OK.
Enter your search terms in the Search field. The results are limited to your search list.
To modify the search scope or to remove the search filter, click Search scope again and modify the filter.
The search list that is currently active is shown at the top of the information center, next to the Search scope link. The search list that you used most recently persists across sessions.
The surrogate key stage in 8.0 can be used with DB Sequences or using a Flat File to manage the keys (set the 'Source Type' option to Flat File). Fortunately, seeding the flat file with the max value of the table is easy, unfortunately it can't be done in the same job as the job that generates the keys.
There are 2 ways to do it --
1. Create a job that does a 'select max(..)' from the target table, connected to a surrogate key stage (set the 'Update Action' to 'Update'). This will seed the state file with the max value. In the job that needs the keys, use the surrogate key stage and this state file to generate keys (SK stage takes 1 input link, and produces 1 output link with the SK column appended). If this is the only thing that inserts rows into the table, you don't need run the 'Update' job again, the state file will remember where it left off for next time.
2. When using a Flat File to manage keys, you can supply an initial value in the surrogate key stage. This value can be a job parameter, so you can hook this together with something that does the select max() and sets the job param in a job sequencer.
BTW -- the new surrogate key operator was designed for the parallel execution environment, so key generation is handled without the use of @PartitionNum or any of that. It also supports multiple jobs (running in parallel) that are getting keys from the same state file.
And finally... you can also use the surrogate key generation functionality directly in a transformer (rather than using the SKG stage). It requires a little set up in the transformer stage properties, then you can use the utility function 'NextSurrogateKey()' as the derivation for the SK column.
If the any of this sounds like something that you want to try, let me know and I can set you up with some simple examples.
Questions: In the sequential file stage on the parallel canvas there is an option to specify a File Name column. This, in theory, allows you to read from multiple files (if the Read Method is set to "File Pattern") and to populate the file name in the specified outbound column.
However, if I specify a wildcard in the File Pattern such as C:\Test_Data\*, I don't get the individual file names in the outbound column - I get C:\Test_Data\* for the file name outbound column. That's rather lame and is a defect if you ask me - anyone else experience this? This is on a windows implementation.
Answer By default the sequential file stage takes all the files returned by the pattern and cats them together reading from one big stream of data, so it is not possible to determine an individual file name for each record.
You can get the individual file names by setting APT_IMPORT_PATTERN_USES_FILESET. This will change the behavior of sequential file stage patterns so it will create a file set with the returned files. This has the advantages of better parallelism depending on configuration and leaves the file names available to populate a file name column.
Issues main_program: Fatal Error: Fatal: Shared library (dsdb2.so) failed to load: errno = (2), system message = ( 0509-022 Cannot load module /opt/IBM/InformationServer/Server/DSComponents/bin/dsdb2.so. 0509-150 Dependent module libdb2.a(shr.o) could not be loaded. 0509-022 Cannot load module libdb2.a(shr.o). 0509-026 System error: A file or directory in the path name does not exist. 0509-022 Cannot load module /opt/IBM/InformationServer/Server/DSComponents/bin/dsdb2.so. 0509-150 Dependent module /opt/IBM/InformationServer/Server/DSComponents/bin/dsdb2.so could not be loaded.)
Resolution Looks like that you are using DB2 plugin. I think that you should put the library path in the dsenv. You will need to stop and re-start the DataStage to pick up the changes in dsenv.
Resolution 1. Depends on what you mean, but I guess the simple answer is, whenever you use the file option with a block size > 1. Which is the 2nd worst performing configuration for it.
2. However, IF you do not use the 'start from highest value' option, then the SKG will backfill the 'gaps' in subsequent runs.
 2. Select the Log View that you use to view your OR logging events in xmeta and Click on "Purge Log" on the left navigation
2. Select the Log View that you use to view your OR logging events in xmeta and Click on "Purge Log" on the left navigation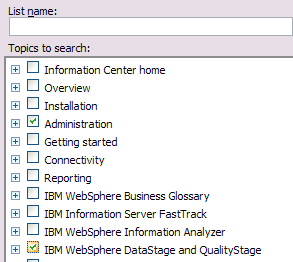
 ) link next to the Search field. The Select Search Scope window opens.
) link next to the Search field. The Select Search Scope window opens. 
